最近在看《深入理解计算机系统》一书,从进程虚拟存储的用户栈和运行时堆可以了解到,进程在开始执行的时候会分配一份较小的内存作为用户栈,而运行时堆会在执行时动态分配内存,相比于栈内存来说堆内存的最大值相对大很多。联想到JavaScript中的栈内存空间和堆内存空间应该也是一样的,但是JavaScript的执行中间多了个引擎(例如V8)的处理,它会不会还是将栈和堆内存分开分配呢?答案是肯定的。
JavaScript调用栈
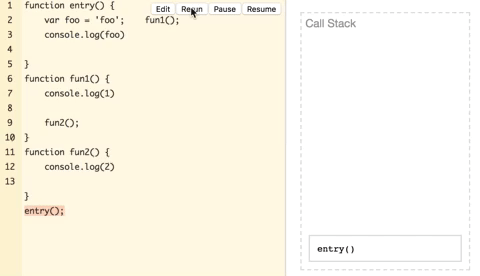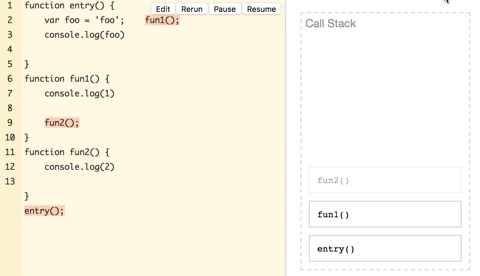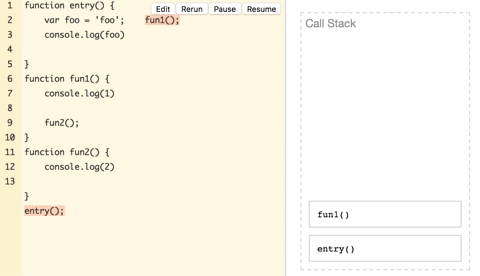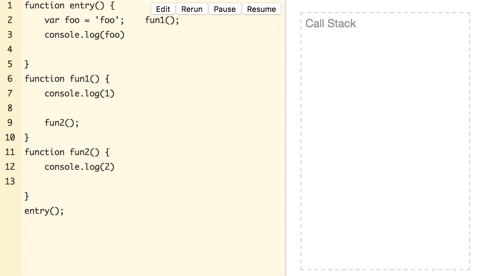
我们所说的JavaScript栈内存,其实就是指它的调用栈,调用栈中保存了函数的调用关系、局部变量和函数参数等信息。关于调用栈大概看一下过程:
上图用到的工具在这里
上图中,entry开始执行压入栈,执行中调用了fun1再将fun1压入,fun1在log(‘1’)之后又将fun2压入,fun2在log(‘2’)之后没有后续的调用,弹出,fun1没有后续调用也弹出,entry后续有log,压入log(foo)操作执行完弹出,然后entry弹出,最终栈清空,执行完毕。上面只是介绍一个抽象的过程,栈里面只是压入了函数和操作,而严格来说,每一个函数调用是压入了一个栈帧,栈帧里面带有局部变量参数等数据,而局部变量就是计算栈内存空间的关键。
JavaScript栈内存空间大小
要计算出栈大小,首先得让栈溢出,写一个递归:
|
|
上面的递归在我的Chrome上跑了15663次就溢出了,然后在上面的代码基础上加一个局部变量:
|
|
可以看到递归次数减少到了13922,这是因为每次函数的调用都在栈帧中多添加了一个Number类型的数据1,它占了8个字节,我们假设不带局部变量的栈帧大小为N,可以得出:
|
|
以上等式可以得出N等于64字节,从而得出栈空间大小:15663*64Bytes = 1002432Bytes < 1M。
从结果可以看出猜想是正确的,1M相对前端应用动不动几十M的内存相比要小了很多,栈和堆内存是分开分配的。
递归栈溢出的解决方法
因为栈的空间限制,递归调用次数有限,比较容易出现溢出。但是堆内存的空间是比较大的,所以对于递归次数较多的调用,其实可以用数组(数组保存在堆内存中)来模拟一个栈,从而达到递归调用的效果。例如有一个单节点的树:
|
|
如果用递归的方法从最后一个节点开始往上逐层输出a,代码是这样:
|
|
毫无疑问这里树的层次超过了栈调用限制将会报错,接下来在数组中模拟调用栈实现:
|
|
上面的代码用stack数组模拟了一个栈,然后把bar压入栈中,判断当前栈顶节点是否存在子节点并且是否hasReturn,存在并且没有hasReturn的话则将子节点压入栈中,否则将栈顶节点弹出,输出元素的a属性并且将栈顶节点下一个节点标识为hasReturn,如此重复判断栈顶元素进行压入和弹出操作直到栈为空。这个过程模拟了函数递归调用栈的作用,防止了递归栈溢出的问题。